GraphQL
GraphQL is a language specification published by Facebook for constructing graph APIs. The specification provides great flexibility in API expression, but also little direction for best practices for common mutation operations. For example, it is silent on how to:
- Create a new object and add it to an existing collection in the same operation.
- Create a set of related, composite objects (a subgraph) and connect it to an existing, persisted graph.
- Differentiate between deleting an object vs disassociating an object from a relationship (but not deleting it).
- Change the composition of a relationship to something different.
- Reference a newly created object inside other mutation operations.
- Perform any combination of the above edits together so they can happen atomically in a single request.
Elide offers an opinionated GraphQL API that addresses exactly how to do these things in a uniform way across your entire data model graph.
JSON Envelope
Elide accepts GraphQL queries embedded in HTTP POST requests. It follows the convention defined by GraphQL for serving over HTTP. Namely, ever GraphQL query is wrapped in a JSON envelope object with one required attribute and two optional attributes:
- query - Required. Contains the actual graphQL query.
- operationName - Used if multiple operations are present in the same query.
- variables - Contains a json object of key/value pairs where the keys map to variable names in the query and the values map to the variable values.
{
"query": "mutation myMutation($bookName: String $authorName: String) {book(op: UPSERT data: {id:2,title:$bookName}) {edges {node {id title authors(op: UPSERT data: {id:2,name:$authorName}) {edges {node {id name}}}}}}}",
"variables": {
"authorName": "John Setinbeck",
"bookName": "Grapes of Wrath"
}
}
The response is also a JSON payload:
{
"data": { ... },
"errors": [ ... ]
}
The ‘data’ field contains the graphQL response object, and the ‘errors’ field (only present when they exist) contains one or more errors encountered when executing the query. Note that it is possible to receive a 200 HTTP OK from Elide but also have errors in the query.
API Structure
GraphQL splits its schema into two kinds of objects:
- Query objects which are used to compose queries and mutations
- Input Objects which are used to supply input data to mutations
The schema for both kinds of objects are derived from the entity relationship graph (defined by the JPA data model). Both contain a set of attributes and relationships. Attributes are properties of the entity. Relationships are links to other entities in the graph.
Input Objects
Input objects just contain attributes and relationship with names directly matching the property names in the JPA annotated model:
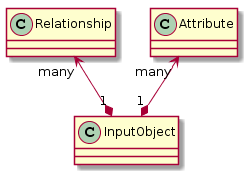
Query Objects
Query Objects are more complex than Input Objects since they do more than simply describe data; they must support filtering, sorting, and pagination. Elide’s GraphQL structure for queries and mutations is depicted below:
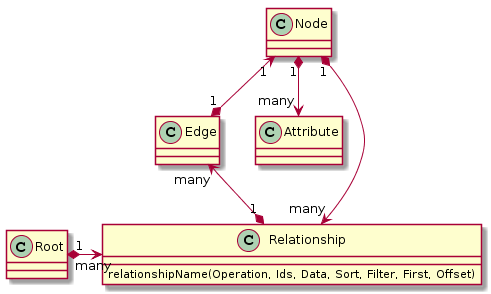
Every GraphQL schema must define a root document which represents the root of the graph. In Elide, entities can be marked if they are directly navigable from the root of the graph. Elide’s GraphQL root documents consist of relationships to these rootable entities. Each root relationship is named by its pluralized type name in the GraphQL root document.
All other non-rootable entities in our schema must be referenced through traversal of the relationships in the entity relationship graph.
Elide models relationships following Relay’s Connection pattern. Relationships are a collection of graph edges. Each edge contains a graph node. The node is an instance of a data model which in turn contains its own attributes and set of relationships.
Relationship Arguments
In GraphQL, any property in the schema can take arguments. Relationships in Elide have a standard set of arguments that either constrain the edges fetched from a relationship or supply data to a mutation:
- The ids parameter is a collection of node identifiers. It is used to select one or more nodes from a relationship.
- The filter parameter is used to build RSQL filter predicates that select zero or more nodes from a relationship.
- The sort parameter is used to order a relationship’s edges by one or more node attributes.
- The parameters offset and first are used to paginate a relationship across multiple API requests.
- The op argument describes the operation to perform on the relationship. When not provided, this argument defaults to a FETCH operation which simply reads the collection of edges.
- The data parameter is provided for operations that mutate the collection (UPSERT, UPDATE, and REPLACE), It contains a list of input objects that match the data type of the relationship. Each data object can be a complex subgraph which contains other objects through nested relationships.
Entity attributes generally do not take arguments.
Relationship Operations
Elide GraphQL relationships support six operations which can be broken into two groups: data operations and id operations. The operations are separated into those that accept a data argument and those that accept an ids argument:
| Operation | Data | Ids |
|---|---|---|
| Upsert | ✓ | X |
| Update | ✓ | X |
| Fetch | X | ✓ |
| Replace | ✓ | X |
| Remove | X | ✓ |
| Delete | X | ✓ |
- The FETCH operation retrieves a set of objects. When a list of ids is specified, it will only extract the set of objects within the relationship with matching ids. If no ids are specified, then the entire collection of objects will be returned to the caller.
- The DELETE operation fully deletes an object from the system.
- The REMOVE operation removes a specified set (qualified by the ids argument) of objects from a relationship. This allows the caller to remove relationships between objects without being forced to fully delete the referenced objects.
- The UPSERT operation behaves much like SQL’s MERGE. Namely, if the object already exists (based on the provided id) then it will be updated. Otherwise, it will be created. In the case of updates, attributes that are not specified are left unmodified. If the data argument contains a complex subgraph of nested objects, nested objects will also invoke UPSERT.
- The UPDATE operation behaves much like SQL’s UPDATE. Namely, if the object already exists (based on the provided id) then it will be updated. Attributes that are not specified are left unmodified. If the data argument contains a complex subgraph of nested objects, nested objects will also invoke UPDATE.
- The REPLACE operation is intended to replace an entire relationship with the set of objects provided in the data argument. REPLACE can be thought of as an UPSERT followed by an implicit REMOVE of everything else that was previously in the collection that the client has authorization to see & manipulate.
Map Data Types
GraphQL has no native support for a map data type. If a JPA data model includes a map, Elide translates this to a list of key/value pairs in the GraphQL schema.
Making Calls
All calls must be HTTP POST requests made to the root endpoint. This specific endpoint will depend on where you mount the provided servlet.
For example, if the servlet is mounted at /graphql, all requests should be sent as:
POST https://yourdomain.com/graphql
Example Data Model
All subsequent query examples are based on the following data model including Book, Author, and Publisher:
@Entity
@Table(name = "book")
@Include(rootLevel = true)
public class Book {
@Id private long id;
private String title;
private String genre;
private String language;
@ManyToMany
private Set<Author> authors;
@ManyToOne
private Publisher publisher;
}
@Entity
@Table(name = "author")
@Include(rootLevel = false)
public class Author {
@Id private long id;
private String name;
@ManyToMany
private Set<Book> books;
}
@Entity
@Table(name = "publisher")
@Include(rootLevel = false)
public class Publisher {
@Id private long id;
private String name;
@OneToMany
private Set<Book> books;
}
Filtering
Elide supports filtering relationships for any FETCH operation by passing a RSQL expression in the filter parameter for the relationship. RSQL is a query language that allows conjunction (and), disjunction (or), and parenthetic grouping of boolean expressions. It is a superset of the FIQL language.
RSQL predicates can filter attributes in:
- The relationship model
- Another model joined to the relationship model through to-one relationships
To join across relationships, the attribute name is prefixed by one or more relationship names separated by period (‘.’)
Operators
The following RSQL operators are supported:
=in=: Evaluates to true if the attribute exactly matches any of the values in the list.=out=: Evaluates to true if the attribute does not match any of the values in the list.==ABC*: Similar to SQLlike 'ABC%.==*ABC: Similar to SQLlike '%ABC.==*ABC*: Similar to SQLlike '%ABC%.=isnull=true: Evaluates to true if the attribute is null=isnull=false: Evaluates to true if the attribute is not null=lt=: Evaluates to true if the attribute is less than the value.=gt=: Evaluates to true if the attribute is greater than the value.=le=: Evaluates to true if the attribute is less than or equal to the value.=ge=: Evaluates to true if the attribute is greater than or equal to the value.=isempty=: Determines if a collection is empty or not.=hasmember=: Determines if a collection contains a particular element.=hasnomember=: Determines if a collection does not contain a particular element.
Examples
- Filter books by title equal to ‘abc’ and genre starting with ‘Science’:
"title=='abc';genre=='Science*' - Filter books with a publication date greater than a certain time or the genre is not ‘Literary Fiction’
or ‘Science Fiction’:
publishDate>1454638927411,genre=out=('Literary Fiction','Science Fiction') - Filter books by the publisher name contains XYZ:
publisher.name==*XYZ*
Pagination
Any relationship can be paginated by providing one or both of the following parameters:
- first - The number of items to return per page.
- offset - The number of items to skip.
Relationship Metadata
Every relationship includes information about the collection (in addition to a list of edges) that can be requested on demand:
- endCursor - The last record offset in the current page (exclusive).
- startCursor - The first record offset in the current page (inclusive).
- hasNextPage - Whether or not more pages of data exist.
- totalRecords - The total number of records in this relationship across all pages.
These properties are contained within the pageInfo structure:
{
pageInfo {
endCursor
startCursor
hasNextPage
totalRecords
}
}
Sorting
Any relationship can be sorted by attributes in:
- The relationship model
- Another model joined to the relationship model through to-one relationships
To join across relationships, the attribute name is prefixed by one or more relationship names separated by period (‘.’)
It is also possible to sort in either ascending or descending order by prepending the attribute expression with a ‘+’ or ‘-‘ character. If no order character is provided, sort order defaults to ascending.
A relationship can be sorted by multiple attributes by separating the attribute expressions by commas: ‘,’.
Model Identifiers
Elide supports three mechanisms by which a newly created entity is assigned an ID:
- The ID is assigned by the client and saved in the data store.
- The client doesn’t provide an ID and the data store generates one.
- The client provides an ID which is replaced by one generated by the data store. When using UPSERT, the client must provide an ID to identify objects which are both created and added to collections in other objects. However, in some instances the server should have ultimate control over the ID that is assigned.
Elide looks for the JPA GeneratedValue annotation to disambiguate whether or not
the data store generates an ID for a given data model. If the client also generated
an ID during the object creation request, the data store ID overrides the client value.
Matching newly created objects to IDs
When using UPSERT, Elide returns object entity bodies (containing newly assigned IDs) in the order in which they were created - assuming all the entities were newly created (and not mixed with entity updates in the request). The client can use this order to map the object created to its server assigned ID.
FETCH Examples
Fetch All Books
Include the id, title, genre, & language in the result.
{
book {
edges {
node {
id
title
genre
language
}
}
}
}
{
"book": {
"edges": [
{
"node": {
"id": "1",
"title": "Libro Uno",
"genre": null,
"language": null
}
},
{
"node": {
"id": "2",
"title": "Libro Dos",
"genre": null,
"language": null
}
},
{
"node": {
"id": "3",
"title": "Doctor Zhivago",
"genre": null,
"language": null
}
}
]
}
}
Fetch Single Book
Fetches book 1. The response includes the id, title, and authors.
For each author, the response includes its id & name.
{
book(ids: ["1"]) {
edges {
node {
id
title
authors {
edges {
node {
id
name
}
}
}
}
}
}
}
{
"book": {
"edges": [
{
"node": {
"id": "1",
"title": "Libro Uno",
"authors": {
"edges": [
{
"node": {
"id": "1",
"name": "Mark Twain"
}
}
]
}
}
}
]
}
}
Filter All Books
Fetches the set of books that start with ‘Libro U’.
{
book(filter: "title==\"Libro U*\"") {
edges {
node {
id
title
}
}
}
}
{
"book": {
"edges": [
{
"node": {
"id": "1",
"title": "Libro Uno"
}
}
]
}
}
Paginate All Books
Fetches a single page of books (1 book per page), starting at the 2nd page.
Also requests the relationship metadata.
{
book(first: "1", after: "1") {
edges {
node {
id
title
}
}
pageInfo {
totalRecords
startCursor
endCursor
hasNextPage
}
}
}
{
"book": {
"edges": [
{
"node": {
"id": "2",
"title": "Libro Dos"
}
}
],
"pageInfo": {
"totalRecords": 3,
"startCursor": "1",
"endCursor": "2",
"hasNextPage": true
}
}
}
Sort All Books
Sorts the collection of books first by their publisher id (descending) and then by the book id (ascending).
{
book(sort: "-publisher.id,id") {
edges {
node {
id
title
publisher {
edges {
node {
id
}
}
}
}
}
}
}
{
"book": {
"edges": [
{
"node": {
"id": "3",
"title": "Doctor Zhivago",
"publisher": {
"edges": [
{
"node": {
"id": "2"
}
}
]
}
}
},
{
"node": {
"id": "1",
"title": "Libro Uno",
"publisher": {
"edges": [
{
"node": {
"id": "1"
}
}
]
}
}
},
{
"node": {
"id": "2",
"title": "Libro Dos",
"publisher": {
"edges": [
{
"node": {
"id": "1"
}
}
]
}
}
}
]
}
}
Schema Introspection
Fetches the entire list of data types in the GraphQL schema.
{
__schema {
types {
name
}
}
}
{
"__schema": {
"types": [
{
"name": "root"
},
{
"name": "noshare"
},
{
"name": "__edges__noshare"
},
{
"name": "__node__noshare"
},
{
"name": "id"
},
{
"name": "__pageInfoObject"
},
{
"name": "Boolean"
},
{
"name": "String"
},
{
"name": "Long"
},
{
"name": "com.yahoo.elide.graphql.RelationshipOp"
},
{
"name": "noshareInput"
},
{
"name": "ID"
},
{
"name": "book"
},
{
"name": "__edges__book"
},
{
"name": "__node__book"
},
{
"name": "authorInput"
},
{
"name": "example.AddressInputInput"
},
{
"name": "example.Author$AuthorType"
},
{
"name": "bookInput"
},
{
"name": "publisherInput"
},
{
"name": "pseudonymInput"
},
{
"name": "author"
},
{
"name": "__edges__author"
},
{
"name": "__node__author"
},
{
"name": "example.Address"
},
{
"name": "publisher"
},
{
"name": "__edges__publisher"
},
{
"name": "__node__publisher"
},
{
"name": "pseudonym"
},
{
"name": "__edges__pseudonym"
},
{
"name": "__node__pseudonym"
},
{
"name": "__Schema"
},
{
"name": "__Type"
},
{
"name": "__TypeKind"
},
{
"name": "__Field"
},
{
"name": "__InputValue"
},
{
"name": "__EnumValue"
},
{
"name": "__Directive"
},
{
"name": "__DirectiveLocation"
}
]
}
}
UPSERT Examples
Create and add new book to an author
Creates a new book and adds it to Author 1. The author’s id and list of newly created books is returned in the response. For each newly created book, only the title is returned.
mutation {
author(ids: ["1"]) {
edges {
node {
id
books(op: UPSERT, data: {title: "Book Numero Dos"}) {
edges {
node {
title
}
}
}
}
}
}
}
{
"author": {
"edges": [
{
"node": {
"id": "1",
"books": {
"edges": [
{
"node": {
"title": "Book Numero Dos"
}
}
]
}
}
}
]
}
}
Update the title of an existing book
Updates the title of book 1 belonging to author 1. The author’s id and list of updated books is returned in the response. For each updated book, only the title is returned.
mutation {
author(ids: ["1"]) {
edges {
node {
id
books(op:UPSERT, data: {id: "1", title: "abc"}) {
edges {
node {
id
title
}
}
}
}
}
}
}
{
"author": {
"edges": [
{
"node": {
"id": "1",
"books": {
"edges": [
{
"node": {
"id": "1",
"title": "abc"
}
}
]
}
}
}
]
}
}
UPDATE Examples
Updates author 1’s name and simultaneously updates the titles of books 2 and 3.
mutation {
author(op:UPDATE, data: {id: "1", name: "John Snow", books: [{id: "3", title: "updated again"}, {id: "2", title: "newish title"}]}) {
edges {
node {
id
name
books(ids: ["3"]) {
edges {
node {
title
}
}
}
}
}
}
}
{
"author": {
"edges": [
{
"node": {
"id": "1",
"name": "John Snow",
"books": {
"edges": [
{
"node": {
"title": "updated again"
}
}
]
}
}
}
]
}
}
DELETE Examples
Deletes books 1 and 2. The id and title of the remaining books are returned in the response.
mutation {
book(op:DELETE, ids: ["1", "2"]) {
edges {
node {
id
title
}
}
}
}
{
"book": {
"edges": [
]
}
}
REMOVE Example
Removes books 1 and 2 from author 1. Author 1 is returned with the remaining books.
mutation {
author(ids: ["1"]) {
edges {
node {
books(op:REMOVE, ids: ["1", "2"]) {
edges {
node {
id
title
}
}
}
}
}
}
}
{
"author": {
"edges": [
{
"node": {
"books": {
"edges": [
]
}
}
}
]
}
}
REPLACE Example
Replaces the set of authors for every book with the set consisting of:
- An existing author (author 1)
- A new author
The response includes the complete set of books (id & title) and their new authors (id & name).
mutation {
book {
edges {
node {
id
title
authors(op: REPLACE, data:[{name:"My New Author"},{id:"1"}]) {
edges {
node {
id
name
}
}
}
}
}
}
}
{
"book": {
"edges": [
{
"node": {
"id": "1",
"title": "Libro Uno",
"authors": {
"edges": [
{
"node": {
"id": "3",
"name": "My New Author"
}
},
{
"node": {
"id": "1",
"name": "Mark Twain"
}
}
]
}
}
},
{
"node": {
"id": "2",
"title": "Libro Dos",
"authors": {
"edges": [
{
"node": {
"id": "4",
"name": "My New Author"
}
},
{
"node": {
"id": "1",
"name": "Mark Twain"
}
}
]
}
}
},
{
"node": {
"id": "3",
"title": "Doctor Zhivago",
"authors": {
"edges": [
{
"node": {
"id": "5",
"name": "My New Author"
}
},
{
"node": {
"id": "1",
"name": "Mark Twain"
}
}
]
}
}
}
]
}
}
Type Serialization/Deserialization
Type coercion between the API and underlying data model has common support across JSON-API and GraphQL and is covered here.